Số học 6 - Xác suất (Probabilities)
Nguồn: HackerEarth
Người dịch: Bùi Việt Dũng
- Các kiến thức cơ bản về Xác suất (Probabilities)
- Biến cố độc lập (Independent Events)
- Xác suất có điều kiện (Conditional Probability)
- Các quy tắc tính xác suất (Rules of Probability)
- Biến cố xung khắc (Mutually Exclusive Events)
- Quy tắc tính xác suất của các biến cố xung khắc
- Xác suất có điều kiện của hai biến cố xung khắc
- Định lí Bayes (Bayes’ Theorem)
- Thuật toán ngẫu nhiên (Randomized Algorithms)
- Đọc thêm
- Bài tập
Các kiến thức cơ bản về Xác suất (Probabilities)
Làm việc với xác suất giống như làm một thí nghiệm. Một kết quả (outcome) là một kết quả của một phép thử hay sự xảy ra hay không xảy ra của một hiện tượng nào đó. Tập hợp tất cả các kết qủa có thể xảy ra của một phép thử được gọi là không gian mẫu (sample space), thường được kí hiệu là $\Omega$. Mỗi kết quả có thể của một phép thử được biểu diễn bởi một và chỉ một điểm trong không gian mẫu.
Một số phép thử ví dụ:
-
Gieo một con súc sắc một lần: Không gian mẫu là $\Omega$ = {1; 2; 3; 4; 5; 6}.
-
Gieo hai đồng xu phân biệt: Không gian mẫu là $\Omega$ = {(Ngửa, Ngửa), (Ngửa, Sấp), (Sấp, Ngửa), (Sấp, Sấp)}.
Ta định nghĩa biến cố (event) là một tập hợp các kết quả của một phép thử. Do đó, một biến cố là một tập con của không gian mẫu. Nếu ta kí hiệu một biến cố là $\Omega_A$, thì $\Omega_A \subset \Omega$. Nếu một biến cố chỉ gồm một kết quả trong không gian mẫu, thì nó được gọi là biến cố đơn. Nếu một biến cố gồm nhiều kết quả trong không gian mẫu thì nó được gọi là biến cố phức.
Thứ mà ta quan tâm nhất là xác suất xảy ra của một biến cố, kí hiệu là $P(A)$. Theo định nghĩa, $P(A)$ là một số thực nằm trong đoạn từ 0 đến 1, với 0 nghĩa là biến cố không thể xảy ra và 1 nghĩa là biến cố chắc chắn xảy ra (nghĩa là biến cố bằng không gian mẫu).
Như đã nói ở trước, mỗi kết qủa được biểu diễn bằng đúng một điểm trong không gian mẫu. Vì thế ta có công thức: $P(A) = \frac{|\Omega_A|}{|\Omega|}$.
Biến cố độc lập (Independent Events)
Hai biến cố được gọi là độc lập với nhau nếu việc xảy ra hay không xảy ra của biến cố này không làm ảnh hưởng tới xác suất xảy ra của biến cố kia.
Ví dụ bạn gieo một con súc sắc và một đồng xu. Xác suất nhận được một số nào đó từ con súc sắc không làm ảnh hưởng đến xác suất đồng xu lật sấp hay lật ngửa. Do đó biến cố gieo con súc sắc được 6 điểm và biến cố đồng xu lật ngửa là hai biến cố độc lập với nhau.
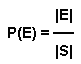
Nếu hai biến cố $A$ và $B$ độc lập với nhau, không biến cố nào ảnh hưởng đến biến cố nào, khi đó ta có thể viết: $P(AB) = P(A).P(B)$.
Xác suất có điều kiện (Conditional Probability)
Xác suất có điều kiện là xác suất của một biến cố $B$ nào đó, biết rằng một biến cố $A$ khác xảy ra. Kí hiệu là $P(B|A)$, đọc là xác suất của $B$, biết $A$.
Sử dụng toán học, ta định nghĩa $P(B|A) = \frac{P(AB)}{P(A)}$.
Các quy tắc tính xác suất (Rules of Probability)
Khi ta phải làm việc với nhiều biến cố, có một vài quy tắc ta phải tuân theo khi tính xác suất của các biến cố này. Các quy tắc này đều phụ thuộc rất lớn vào việc các biến cố này có độc lập với nhau hay không. Đầu tiên, cho ba biến cố $A, B, C$, biến cố $S :$ "$A$ hoặc $B$ hoặc $C$ xảy ra" được kí hiệu là $A \cup B \cup C$, có xác suất $P(S) = P(A \cup B \cup C)$.
Quy tắc nhân xác suất (Multiplication Rule) ($AB$)
$AB$ có nghĩa là giao của hai biến cố $A$ và $B$, và trong xác suất, $AB$ là biến cố "Cả $A$ và $B$ cùng xảy ra". Khi ta sử dụng từ "và", ta nghĩ đến phép nhân, vì vậy "$A$ và $B$" có thể được viết dưới dạng $A \times B$ và $A.B$.
Nếu $A$ và $B$ là hai biến cố phụ thuộc, xác suất của biến cố $AB$ được tính bằng công thức: $P(AB) = P(A \cup B) - (P(\text{chỉ } A) + P(\text{chỉ } B))$
Nếu $A$ và $B$ là hai biến cố độc lập, xác suất của biến cố $AB$ được tính bằng công thức: $P(AB) = P(A).P(B)$.
Do đó, xác suất có điều kiện của hai biến cố độc lập có thể được tính bằng công thức: $P(B|A) = \frac{P(AB)}{P(A)} \Leftrightarrow P(B|A) = \frac{P(A).P(B)}{P(A)} \Leftrightarrow P(B|A) = P(B)$.
Công thức trên phù hợp với định nghĩa xác suất có điều kiện, biến cố $A$ có xảy ra hay không không làm ảnh hưởng đến xác suất xảy ra biến cố $B$, do đó xác suất biến cố $B$ xảy ra biết biến cố $A$ xảy ra bằng xác suất xảy ra biến cố $B$.
Quy tắc cộng xác suất (Additive Rule) ($A \cup B$)
Trong xác suất, ta liên tưởng phép cộng như từ "hoặc". Gọi biến cố $A \cup B$ là biến cố "$A$ hoặc $B$ xảy ra", xác suất của biến cố $A \cup B$ được tính bằng công thức: $P(A \cup B) = P(A) + P(B) - P(AB)$ do $|A \cup B| = |A| + |B| - |A \cap B|$.
Nhưng hãy nhớ lại phần lí thuyết tập hợp và cách chúng ta định nghĩa không gian mẫu ở trên, gọi $C = (A \cap B)'$, khi đó ta có $P(A \cup B) = 1 - P(C)$.
Biến cố xung khắc (Mutually Exclusive Events)
Hai biến cố được gọi là xung khắc hoặc rời nhau nếu không có một kết quả nào của phép thử làm chúng cùng lúc xảy ra. Nếu $A$ và $B$ là hai biến cố xung khắc, thì $A \cap B = \varnothing $
Nếu ba biến cố $A$, $B$, $C$ xung khắc với nhau, ta cũng có $A \cap B \cap C = \varnothing$.
Quy tắc tính xác suất của các biến cố xung khắc
Quy tắc nhân xác suất
Từ định nghĩa các biến cố xung khắc, dễ dàng có được $P(AB) = 0$.
Quy tắc cộng xác suất
Như chúng ta đã định nghĩa ở trên, công thức cộng xác suất hai biến cố xung khắc có dạng: $P(A \cup B) = P(A) + P(B)$.
Quy tắc trừ xác suất (Subtraction Rule)
Từ quy tắc cộng, ta suy ra được quy tắc trừ hai biến cố xung khắc: $P(A \cup B)' = 1 - P(A) - P(B)$.
Xác suất có điều kiện của hai biến cố xung khắc
Ta đã định nghĩa xác suất có điều kiện bằng công thức sau: $P(B|A) = \frac{P(AB)}{P(A)}$
Mà với hai biến cố xung khắc $A$ và $B$, ta lại có: $P(AB) = 0$
Do đó $P(B|A) = \frac{0}{P(A)} = 0$.
Định lí Bayes (Bayes’ Theorem)
Trong xác suất và thống kê, định lí Bayes mô tả xác suất của một biến cố dựa trên các biến cố có liên quan đến biến cố đó.
Công thức của định lí Bayes như sau: $P(A|B) = \frac{P(A).P(B|A)}{P(B)}$, với $A$, $B$ là hai biến cố, $P(A)$, $P(B)$ là xác suất của hai biến cố, $P(A|B)$ là xác suất có điều kiện: xác suất của $A$ biết $B$ xảy ra, $P(B|A)$ là xác suất của $B$ biết $A$ xảy ra.
Dạng mở rộng (Extended Form)
Cho $n$ biến cố $A_1, A_2, …, A_n$, khi đó nếu $P(B) = \sum_{i=1}^n P(B|A_i)P(A_i)$ thì $P(A_i|B) = \frac{P(B|A_i)P(A_i)}{\sum_{j=1}^n P(B|A_j)P(A_j)}$.
Thuật toán ngẫu nhiên (Randomized Algorithms)
Ta gọi thuật toán ngẫu nhiên là thuật toán sử dụng các số ngẫu nhiên để quyết định trong lúc chạy. Không giống thuật toán tất định (deterministic algorithms) mà với một bộ dữ liệu nhất định, thuật toán luôn ra một kết quả và chạy trong cùng một lượng thời gian, thuật toán ngẫu nhiên chạy ra kết quả khác nhau ở những lần chạy khác nhau. Ta thường chia thuật toán ngẫu nhiên ra làm hai loại:
-
Thuật toán Monte Carlo (Monte Carlo algorithms): Có thể ra kết quả sai - chúng ta sẽ tính xác suất ra kết quả sai để quyết định có dùng nó hay không.
-
Thuật toán Las Vegas (Las Vegas algorithms): Luôn chạy ra kết quả đúng, nhưng thời gian chạy sẽ khác nhau với cùng một bộ dữ liệu.
Mục tiêu của việc xây dựng các thuật toán ngẫu nhiên là giảm thời gian cài đặt thuật toán và đôi khi tạo ra những lời giải ngắn gọn hơn trong bài toán. Thuât toán ngẫu nhiên còn có khả năng giải các bài toán cực khó. Vì vậy, các thuật toán ngẫu nhiên đã trở thành một vấn đề được nhiều nhà khoa học nghiên cứu và đã được ứng dụng để giải nhiều bài toán khác nhau.
Một bài toán có thể có nhiều lời giải, một số lời giải trong số đó là tối ưu. Phương pháp làm cổ điển là xét từng phần tử một, theo thứ tự trong dữ liệu vào. Tuy nhiên, ta không thể chắc chắn các phần tử thuận lợi được phân bố đều trong dữ liệu vào. Vì vậy, thuật toán định tất có thể không tìm ra lời giải trong thời gian đủ nhanh. Lợi thế của thuật toán ngẫu nhiên là không có thứ tự duyệt các phần tử cố định và trong mọi trường hợp, thuật toán ngẫu nhiên có thể hoạt động tốt hơn.
Đọc thêm
Các bạn cũng có thể đọc thêm bài này - có thêm 1 số kiến thức nâng cao và 1 số ví dụ về giải bài.